








Vous n’en avez pas forcément tout le temps conscience mais la computer vision fait partie de votre quotidien. De Google Maps, à l’imagerie médicale en passant par les filtres SnapChat la Computer Vision est aussi diverse dans ses domaines d’application que dans sa sophistication.
Dans cet article, nous allons explorer les origines de la computer vision, son fonctionnement, ses applications, les entreprises les plus influentes dans le domaine ainsi que les défis à relever.
Computer Vision : les origines
Les premières recherches en computer vision ont commencé dans les années 1960, lorsque les scientifiques ont cherché à développer des algorithmes pour extraire des informations à partir d’images numériques. À cette époque, les ordinateurs n’étaient pas suffisamment puissants pour traiter de grandes quantités de données visuelles, et les algorithmes étaient rudimentaires. Cependant, ces premiers travaux ont jeté les bases de la vision par ordinateur moderne.
Au cours des années 1970 et 1980, des progrès ont été réalisés dans la reconnaissance de formes, la détection de contours et la segmentation d’images. Ces avancées ont permis le développement de systèmes de reconnaissance faciale, de numérisation de documents et de reconnaissance optique de caractères (OCR).
Dans les années 1990 et 2000, l’avènement de l’informatique puissante et des algorithmes d’apprentissage automatique ont permis de nouveaux développements dans la vision par ordinateur. Les réseaux de neurones profonds, en particulier, ont permis des avancées significatives dans la reconnaissance d’objets, la détection de mouvement et la compréhension de la scène.
Au cours des décennies suivantes, la puissance de calcul des ordinateurs a augmenté de façon exponentielle, ce qui a permis le développement d’algorithmes de plus en plus sophistiqués pour la vision par ordinateur. Les avancées les plus significatives ont été réalisées grâce à l’apprentissage automatique, une technique qui permet aux ordinateurs d’apprendre à partir de données sans instruction explicite.
Qu’est-ce que la Computer Vision ?
Définition de la Computer vision
La vision par ordinateur, ou computer vision, est une technique d’intelligence artificielle qui consiste à permettre aux ordinateurs de « voir » et d’interpréter les images et vidéos de la même manière que le font les êtres humains.
Comme la NLP pour le texte, la computer vision s’appuie sur des algorithmes mathématiques et statistiques pour extraire des informations à partir d’images et de vidéos, et les interpréter de manière significative.
Comment cela fonctionne ?
Ces algorithmes utilisent majoritairement des réseaux de neurones, et notamment les CNN.
Les algorithmes de vision par ordinateur s’inspirent donc du fonctionnement du cerveau humain. Les scientifiques ont étudié le fonctionnement du cortex visuel, la partie du cerveau qui traite les informations visuelles, pour développer des algorithmes qui reproduisent certains aspects de la perception humaine.
Pourquoi parlons-nous de neurones ?
Par exemple, les réseaux de neurones artificiels sont des algorithmes de vision par ordinateur qui s’inspirent du fonctionnement des neurones du cerveau.
Les réseaux de neurones sont des structures complexes de nœuds interconnectés qui sont capables de traiter de grandes quantités de données en parallèle. Les neurones artificiels sont modélisés sur les neurones biologiques, et ils sont activés lorsque certaines conditions sont remplies.
Les réseaux de neurones peuvent être entraînés à partir de données en utilisant des techniques d’apprentissage automatique, ce qui leur permet de reconnaître des motifs dans les données et d’effectuer des tâches de vision par ordinateur complexes.
Quels sont les outils utilisés en computer vision ?
Il existe plusieurs bibliothèques logicielles utilisées en Computer Vision pour la programmation, l’analyse et le traitement des images. Voici quelques-unes des bibliothèques les plus populaires :
OpenCV : OpenCV (Open Source Computer Vision Library) est une bibliothèque open source écrite en C++ qui fournit des outils pour la vision par ordinateur, y compris l’acquisition d’images, le traitement d’images, la segmentation d’images, la reconnaissance d’objets, la détection de visages, etc. OpenCV est disponible dans plusieurs langages, y compris Python, Java, C# et MATLAB.
TensorFlow : TensorFlow est une bibliothèque open source de deep learning développée par Google, qui permet la création et l’entraînement de modèles de réseaux de neurones pour la vision par ordinateur. TensorFlow est disponible dans plusieurs langages, y compris Python, C++, Java, JavaScript et Swift.
PyTorch : PyTorch est une bibliothèque open source de deep learning développée par Facebook, qui permet la création et l’entraînement de modèles de réseaux de neurones pour la vision par ordinateur. PyTorch est disponible dans Python.
Keras : Keras est une bibliothèque open source de deep learning qui fournit une interface conviviale pour la création, l’entraînement et le déploiement de modèles de réseaux de neurones pour la vision par ordinateur. Keras est disponible dans Python.
Caffe : Caffe est une bibliothèque open source de deep learning écrite en C++, qui est principalement utilisée pour la classification d’images, la détection d’objets et la segmentation d’images. Caffe est disponible dans plusieurs langages, y compris Python et MATLAB.
Ces bibliothèques sont régulièrement mises à jour et sont utilisées par la communauté de la vision par ordinateur pour résoudre diverses tâches et problèmes.
Quelles sont les types d’algorithmes utilisés ?
Il existe quatre grandes catégories d’algorithmes utilisés par la computer vision :
- La détection d’objects
- La segmentation d’images
- La classification d’images
- La reconnaissance de formes, d’images ou de mouvements
Les algorithmes de détection d’objet
Cette catégorie d’algorithmes est utilisée pour détecter la présence d’objets spécifiques dans une image ou une vidéo. Les algorithmes de détection d’objets sont souvent utilisés dans les applications de surveillance, de reconnaissance de visages et de reconnaissance de plaques d’immatriculation. Les algorithmes populaires de détection d’objets incluent YOLO, Faster R-CNN et RetinaNet.
Il existe plusieurs algorithmes de détection d’objets qui sont largement utilisés en computer vision. Voici quelques exemples :
- R-CNN (Region-based Convolutional Neural Networks) : ce modèle est l’un des premiers modèles de détection d’objets basés sur des réseaux de neurones convolutifs (CNN). Il utilise une région proposée pour extraire des caractéristiques et les utiliser pour la classification.
- YOLO (You Only Look Once) : ce modèle est un autre modèle de détection d’objets basé sur des CNN. Il utilise un réseau de neurones unique pour détecter des objets et prédire leurs boîtes englobantes et leurs classes.
- SSD (Single Shot Detector) : ce modèle est également basé sur des CNN et est conçu pour détecter des objets dans des images en temps réel. Il utilise des filtres de convolution à différentes échelles pour détecter des objets de différentes tailles.
- Faster R-CNN : cette variante du modèle R-CNN utilise une méthode de régionalisation basée sur des CNN pour détecter des objets et prédire leurs boîtes englobantes.
- Mask R-CNN : ce modèle est une extension de Faster R-CNN qui permet également la segmentation d’images en plus de la détection d’objets. Il utilise une approche multi-tâches pour détecter des objets, prédire leurs boîtes englobantes et segmenter l’image en même temps.
Les algorithmes de segmentation d’images
Cette catégorie d’algorithmes est utilisée pour diviser une image en plusieurs segments ou régions, afin de faciliter l’analyse et la compréhension de l’image. Les algorithmes de segmentation d’images sont souvent utilisés dans les applications de traitement d’images médicales, de surveillance et de reconnaissance de formes. Les algorithmes populaires de segmentation d’images incluent U-Net, Mask R-CNN et FCN.
ll existe plusieurs algorithmes de segmentation d’images utilisés en computer vision. Voici quelques exemples :
- K-means clustering : cette méthode de segmentation d’images utilise l’algorithme de clustering K-means pour diviser une image en plusieurs régions en fonction des couleurs ou des intensités de pixels. Les régions sont ensuite assignées à des étiquettes pour identifier les différentes parties de l’image.
- Watershed segmentation : cette méthode de segmentation d’image utilise des gradients d’intensité pour diviser l’image en différentes régions. Elle est souvent utilisée pour la segmentation de régions contenant des bordures ou des lignes.
- Graph cut : cette méthode de segmentation d’image utilise des graphes pour définir les frontières entre les différentes régions. Elle est souvent utilisée pour la segmentation d’objets dans des images.
- Convolutional neural networks (CNN) : ces algorithmes de segmentation d’image utilisent des réseaux de neurones pour identifier les régions d’intérêt dans une image. Les CNNs sont souvent utilisés pour la segmentation d’images médicales, comme la segmentation de tumeurs dans des images de tomographie par ordinateur (CT) ou d’IRM.
- U-Net : cette architecture de réseau de neurones est spécifiquement conçue pour la segmentation d’images biomédicales. Elle utilise une architecture d’encodeur-décodeur pour capturer les caractéristiques de l’image à plusieurs niveaux de résolution et produire des masques de segmentation précis.
Les algorithmes de classification d’images
Cette catégorie d’algorithmes est utilisée pour classifier les images en différentes catégories. Les algorithmes de classification d’images sont souvent utilisés dans les applications de reconnaissance d’objets, de détection de fraudes et de tri automatique des déchets. Les algorithmes populaires de classification d’images incluent VGG, Inception et ResNet.
Il existe plusieurs algorithmes de classification d’images utilisés en computer vision. Voici quelques exemples :
- Réseaux de neurones profonds (Deep Neural Networks, DNN) : ces algorithmes de classification utilisent des réseaux de neurones à plusieurs couches pour apprendre les caractéristiques de l’image à partir des pixels bruts. Les réseaux de neurones convolutifs (CNN) sont souvent utilisés pour la classification d’images.
- SVM (Support Vector Machine) : cet algorithme est utilisé pour la classification binaire et multi-classes en utilisant un hyperplan de séparation. Il est souvent utilisé pour la classification d’images basée sur des caractéristiques extraites de l’image, comme les descripteurs SIFT ou HOG.
- Random Forest : cet algorithme est un ensemble d’arbres de décision utilisé pour la classification d’images. Il est souvent utilisé pour la classification basée sur des caractéristiques extraites de l’image, comme les descripteurs SIFT ou HOG.
- Réseaux de neurones récurrents (Recurrent Neural Networks, RNN) : ces algorithmes sont utilisés pour la classification de séquences d’images, telles que des vidéos. Les réseaux de neurones récurrents peuvent capturer la dépendance temporelle entre les images et améliorer la classification.
- Réseaux de neurones résiduels (Residual Neural Networks, ResNet) : ces algorithmes de classification utilisent des blocs résiduels pour améliorer la performance des réseaux de neurones profonds. Ils sont souvent utilisés pour la classification d’images à grande échelle.
Les algorithmes de reconnaissance
Les algorithmes de reconnaissance de formes, d’images ou de mouvements sont souvent utilisés pour la reconnaissance de formes et la détection de mouvements dans des applications telles que la surveillance vidéo, la reconnaissance de gestes, la reconnaissance d’activités humaines et la réalité augmentée.
Il existe plusieurs algorithmes de reconnaissance de forme d’images et de mouvements utilisés en computer vision. Voici quelques exemples :
- Template matching : cette méthode de reconnaissance de forme utilise une image modèle pour trouver des occurrences de cette forme dans une image cible. C’est une méthode simple mais souvent peu robuste aux variations d’échelle, de rotation et d’éclairage.
- Contours actifs (Active contours) : cette méthode de reconnaissance de forme utilise des contours actifs, également appelés snakes, pour détecter les bords d’objets dans une image. Les contours actifs peuvent être déformés pour épouser la forme de l’objet à détecter.
- Algorithmes de détection de mouvement : ces algorithmes sont utilisés pour détecter les mouvements dans des séquences d’images. Les algorithmes les plus courants utilisent des techniques de différence d’images ou de flux optique pour détecter les changements dans la scène.
- Réseaux de neurones convolutifs (CNN) : ces algorithmes sont également utilisés pour la reconnaissance de forme et la détection de mouvement. Les CNNs peuvent apprendre à détecter des caractéristiques pertinentes dans une image ou une séquence d’images pour identifier des objets ou des mouvements spécifiques.
- Algorithmes de reconnaissance de mouvements humains : ces algorithmes sont spécifiquement conçus pour la reconnaissance de mouvements humains, tels que la détection de gestes ou la reconnaissance d’activités humaines. Ces algorithmes utilisent souvent des réseaux de neurones, des modèles de Markov cachés ou des SVM pour la reconnaissance de mouvements.
Bien entendu, ces catégories ne sont pas mutuellement exclusives et il existe souvent un chevauchement entre elles. Par exemple, la détection d’objets peut être considérée comme une forme de reconnaissance d’images, car elle utilise des caractéristiques de l’image pour identifier les objets.
De même, la reconnaissance de mouvements peut également être considérée comme une forme de segmentation d’images, car elle divise une vidéo en différentes régions en fonction du mouvement des objets.
De plus, des algorithmes sont souvent combinés pour résoudre des tâches plus complexes. Par exemple, un CNN peut être utilisé pour extraire des caractéristiques d’une image, qui sont ensuite alimentées à un RNN pour l’analyse de séquence.
Quels sont les domaines d’application de la Computer Vision ?
Comme nous le disions en introduction, la Computer Vision est omniprésente dans la technologie d’aujourd’hui. Il est donc compliqué de dresser une liste totalement exhaustive de ses domaines d’applications. En effet, de plus en plus, des domaines et produits basent leur construction et/ou leur développement technologique sur la computer vision.
Pour quels secteurs d’activité ?
Ainsi, chaque secteur d’activité peut en retirer des avantages :
- Retail : contrôle qualité et diagnostiques
- Industrie : analyse du client et de son parcours
- Construction : sécurité des chantiers par la vérification du port des EPI, alterting intelligent concernant l’intrusion
- Logistique : suivi et optimisation des flux de marchandises
- Assurance : évaluation automatisée des dommages, digitalisation automatique de dossiers manuscrits
- Secteur public : optimisation des files d’attente
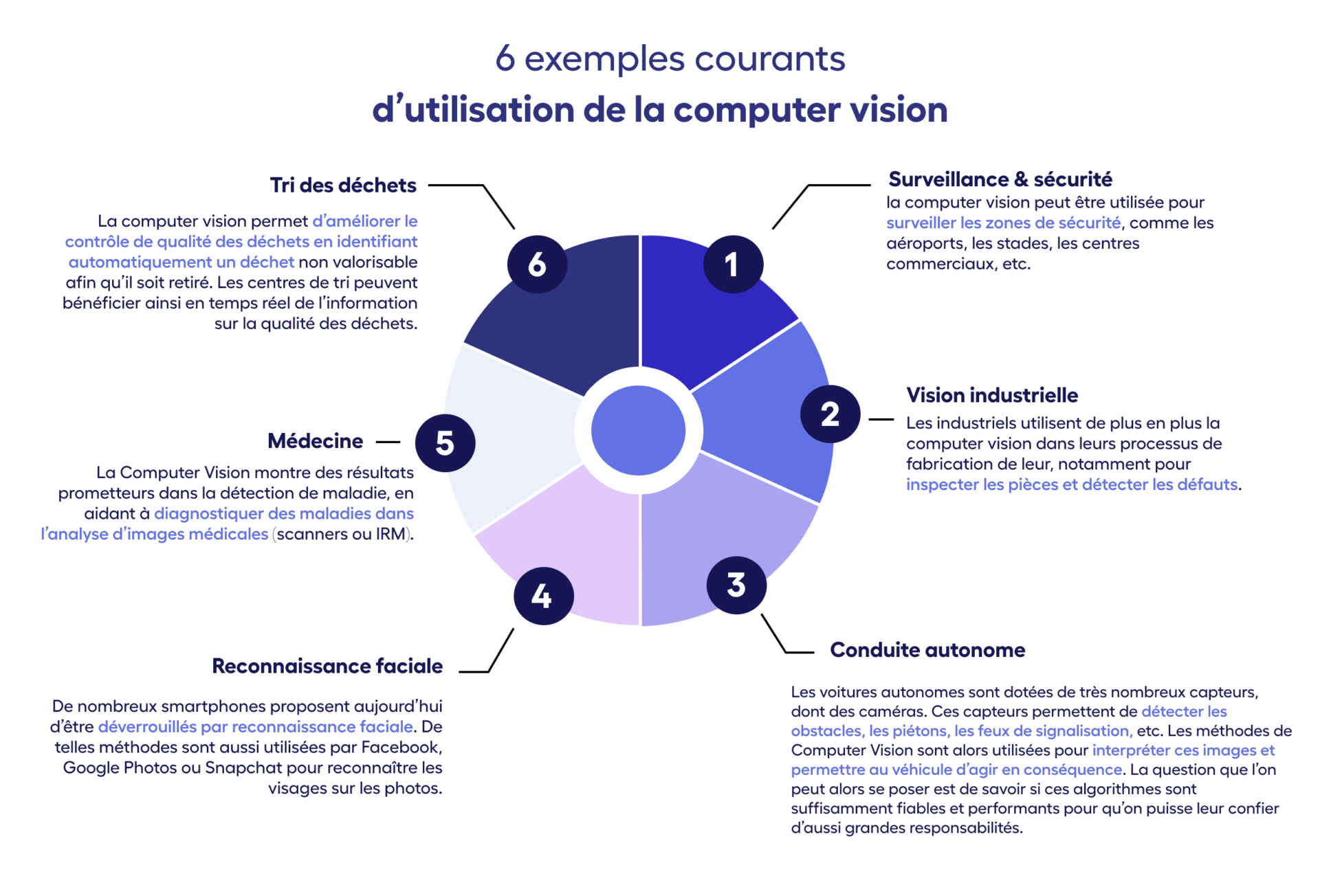
6 exemples courants d’utilisation de la computer vision
L’objectif est de vous donner un aperçu de la grande diversité des domaines où la Computer Vision peut s’appliquer. Voici donc 6 exemples les plus courants d’utilisation de la computer vision. On compte là-dedans des cas d’utilisation en Surveillance & sécurité, Vision industrielle, Conduite autonome, Reconnaissance faciale, Médecine, Tri des déchets.
Principales entreprises de la Computer Vision
De nombreux géants sont actifs dans le domaine de la computer vision, comme par exemple Google avec des produits tels que Google Lens et Google Photos, Microsoft avec Microsoft Azure et Microsoft HoloLens, Amazon avec Amazon Rekognition et Amazon Go ou encore NVIDIA est un fabricant de cartes graphiques qui fournit des processeurs pour l’apprentissage en profondeur et la vision par ordinateur.
Pour aller plus loin : l’annuaire des start-up Computer Vision de la French Tech
Quels sont les enjeux et défis de la Computer Vision
Les limites actuelle de ces applications
Le sens commun
Malgré tous ces progrès, les réseaux de neurones sont très loin de remplacer complètement l’humain. En effet, si on arrive à produire des systèmes qui peuvent conduire une voiture, jouer aux échecs ou accomplir d’autres tâches difficiles de manière plus fiable et rapide que la plupart des humains, ces systèmes restent très spécialisés.
Ce qui manque aussi aux machines, c’est le sens commun, et la capacité à l’intelligence générale qui permet d’acquérir de nouvelles compétences, quel qu’en soit le domaine.
Le manque d’adaptabilité
Si vous souhaitez appliqué à un nouveau cas d’usage, vous devez aire du « fine tuning« . Il est également impossible de s’adapter à des « concept drift« , des changements de contexte qui n’ont pas été vus à l’entraînement. La computer vision a donc du mal à s’adapter à des situations nouvelles ou imprévues. Il est important de développer des algorithmes qui peuvent s’adapter à des situations imprévues.
Les défis techniques
La faible volumétrie de volumes de données
Il faut spécialiser les modèles donc vous avez besoin, et apprendre à votre modèle ce qu’il doit rechercher dans l’image, ce qui engendre des coûts d’acquisition et de labélisation de ces données.
Les conditions d’exploitation différentes
Il existe des dispositifs de capture variés (optique, caméra..), dans des conditions d’environnement différents (angle, luminosité, météo…). Il peut donc y avoir des écarts entre la situation d’entraînement et d’inférence.
La performance (temps réel)
De nombreux cas d’usage nécessitent une inférence rapide, qui peut être limitée par les capacités de stockage ou de calculs (processeur).
Les autres défis
La précision
La précision de la computer vision dépend de la qualité des données d’entrée et des algorithmes utilisés. Il est important d’améliorer constamment la précision pour éviter les erreurs.
L’éthique :
la computer vision soulève des questions éthiques, notamment en ce qui concerne la vie privée et la discrimination. Il est important de mettre en place des réglementations pour s’assurer que la technologie est utilisée de manière éthique.
L’Interprétabilité :
la computer vision peut être difficile à interpréter, car les algorithmes peuvent prendre en compte des facteurs inattendus ou biaisés. Il est important de comprendre comment les algorithmes prennent des décisions pour éviter les biais.
Pour aller plus loin : Dossier – Intelligence Artificielle, des tendances et des enjeux
La computer vision est une technologie passionnante qui permet aux ordinateurs de comprendre et d’interpréter le monde visuel qui les entoure. La technologie a de nombreuses applications, allant de la reconnaissance faciale à la conduite autonome. Les entreprises telles que Google, Microsoft, Amazon et NVIDIA sont des leaders dans le domaine de la computer vision. Cependant, il y a encore des défis à relever, notamment en ce qui concerne la précision, l’éthique, l’interprétation et l’adaptabilité. Malgré ces défis, la computer vision continue de se développer et promet de transformer notre façon de voir et d’interagir avec le monde.
Maintenant que vous savez tout ce qu’il savoir sur la computer vision, optez pour une expertise et approfondissez vos connaissances en Data et IA avec nos formations !
Cela pourrait vous intéresser



Connect
Pour recevoir nos derniers articles sur la Data et l'Intelligence Artificielle, abonnez vous à Connect, l’email qui fait du bien à vos données.
