







Chaque seconde, ce sont 1,7 mégaoctets de données qui sont générés pour chaque personne sur Terre. Avec un tel volume de data, il devient crucial pour les organisations d’optimiser leur collecte, leur structuration et leur analyse. Et en conséquence, ces dernières années, le Big Data a alimenté une demande croissante d’experts en data science, ainsi qu’une nouvelle définition de l’usage de la donnée en entreprise.
Aujourd’hui, le domaine de la science des données domine le classement LinkedIn des jobs émergents avec une croissance des recrutements de 37 % au cours des trois dernières années.
La science des données révolutionne désormais presque tous les secteurs et processus des grandes entreprises. Pourtant, ce secteur d’activité reste encore flou et il est parfois difficile de donner à la Data Science une définition. Pour mieux comprendre son importance et ses enjeux pour l’avenir, le mieux reste de commencer à comprendre ce qu’elle englobe !
Qu’est-ce la Data Science : définition
Plus que de la théorie, une discipline appliquée
La science des données est le domaine d’application des techniques d’extraction et d’analyse avancée des données.
Plus qu’un domaine théorique, la data science est une discipline appliquée, dans laquelle les données facilitent la prise de décision, la planification stratégique, et plus globalement tous les processus d’une organisation, quelle que soit sa nature ou son secteur d’activité.
Data Science, comment extraire de la valeur aux données ?
La DataScience – ou bien science des données – regroupe un large ensemble d’outils et techniques multidisciplinaires – visant à extraire de l’information exploitable de données brutes.
La Data Science avec ces méthodes multiples a pour objectif d’identifier des tendances, mettre en lumière des motifs des relations/corrélations entre les données.
A l’interface entre la programmation informatique et les mathématiques, la data science use d’outils tels que l’analyse prédictive ou l’optimisation en se basant sur les statistiques et l’intelligence artificielle incluant des algorithmes de machine learning par exemple.
Quelles différences entre Data Science, Intelligence Artificielle, Machine Learning ou Deep Learning ?
Afin de mieux appréhender la Data Science, il est important de connaître d’autres concepts clés liés à ce domaine, comme l’Intelligence Artificielle, le Machine Learning ou le Deep Learning. En effet, ces notions sont bien souvent utilisées de manière interchangeable, mais des nuances existent :
- L’IA, intelligence artificielle, est l’ensemble de théories et techniques développant des programmes informatiques capables de simuler des comportements humains (raisonnement, apprentissage…)
- Le Machine Learning est, selon la définition d’Arthur Samuel en 1959 le « champ d’étude qui donne aux ordinateurs la capacité d’apprendre sans être explicitement programmés à apprendre »
- Le Deep Learning est un sous-ensemble du Machine Learning, qui permet aux ordinateurs de résoudre des problèmes plus complexes.
Comment transformer la data en insight ?
Aujourd’hui, presque toutes les entreprises déclarent pratiquer la data science sous une forme ou une autre. Cependant, les méthodes et les approches utilisées varient sensiblement selon les organisations ! Alors concrètement , comment valoriser la donnée brute en insight ?Si l’on reprend la cartographie d’un projet Data, voici les étapes.
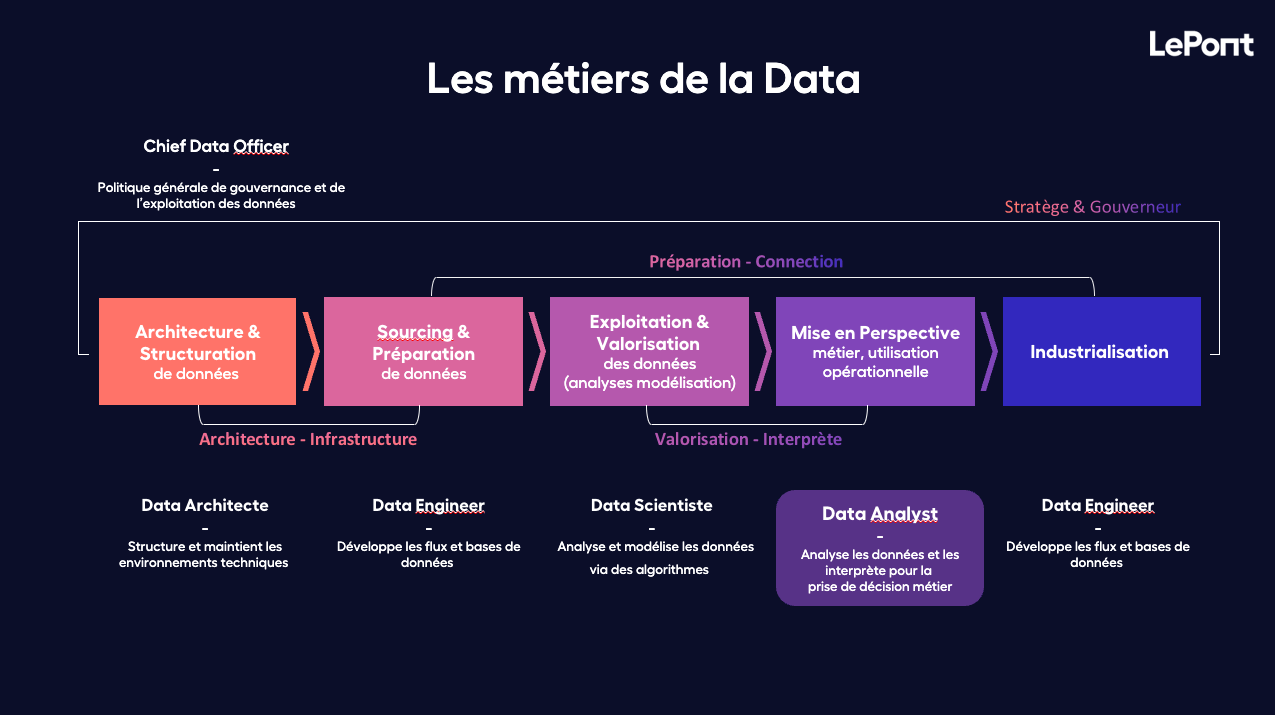
Phase d’architecture et infrastructure de la donnée
Une première étape consiste en l’extraction et la structuration de la donnée. L’enjeu de cette étape réalisée par le Data Architecte, réside dans la structuration et le maintien des environnements techniques. En effet, différentes méthodes d’extraction et de manipulation sont à considérer suivant leur volume.
Phase de préparation de la donnée
Sourcing et préparation de données : S’ensuit la phase de traitement de donnée : dite Data Cleaning (ou cleansing) ayant comme objectif de mettre en qualité la donnée avant de pouvoir l’enrichir. A cette étape, le Data Engineer s’occupe du développement des flux des bases de données. Il analyse et modélise les données via des algorithmes.
Phase de valorisation et interprétation de la donnée
Exploitation et valorisation de données : le Data enrichment. Cette phase est extrêmement importante – si ce n’est la plus importante – car c’est à ce moment que le Data Scientiste fait usage de l’ensemble des outils et techniques qui sont à sa disposition pour valoriser la donnée.
Croisement, combinaison, transformation, clustering une multitude de méthodes est utilisé afin de pouvoir constituer un ensemble des indicateurs cohérents et significatif pour son métier.
Suivant le type de données auquel le data scientiste est confronté et suivant les problématiques métiers différentes méthodes peuvent être utilisées: Clustering, Statistique, Data ou Text mining … Suivant les situations la phase de Data Enrichment se recouvre avec celle de l’analyse.
Phase d’analyse de la donnée
Mise en perspective de la donnée : durant la phase d’analyse des données, le Data Analyste va un peu plus loin dans l’exploitation des données. En effet, il peut utiliser des algorithmes d’optimisation ou de machine learning afin de faire de la prédiction ou bien de la recommandation.
Enfin, les méthodes et outils de Data Visualisation sont essentielles au data analyste puisque cela lui offre la possibilité de pouvoir communiquer simplement ses résultats d’analyse.
Pourquoi la science des données est-elle si importante pour l’entreprise ?
Selon IDC, d’ici 2025, le volume des données mondiales aura atteint 175 zettaoctets. La data science est donc un précieux outil pour le Big Data : comme nous l’avions mentionné dans sa définition, elle permet notamment aux organisations d’exploiter cette mine d’informations.
La science des données est largement utilisée dans divers domaines et secteurs d’activité, allant du marketing à la santé, et en passant par la finance, la politique ou encore l’agronomie. C’est d’ailleurs précisément parce qu’elle est si transversale, que la data science a une telle importance.
S’il est impossible de résumer ici toutes ses applications, on peut plus facilement analyser le caractère stratégique de la data science en affaires. Elle permet en effet aux entreprises de mesurer, suivre et optimiser leurs performances en améliorant leurs produits et services. Mais elle joue aussi un rôle crucial dans presque tous les aspects opérationnels et commerciaux de leur activité !
Autrement dit, la science des données étaye chaque décision stratégique d’une organisation, en prouvant sa pertinence et son efficacité. Elle permet également de mesurer les résultats de chaque action entreprise et de tirer des leçons du passé !
Quelles sont les applications de la data science ?
Pour mieux saisir la définition de ce qu’est la data science, le mieux reste de s’intéresser à ses applications concrètes ! Nous vous proposons donc de plonger dans 4 secteurs d’application tangibles que la science des données peut améliorer…
La data science au service de la définition des persona
Les marques disposent généralement de nombreuses sources de données sur leurs clients (potentiels ou actuels). Réseaux sociaux, site web, produit, support client… sont autant de points de récolte de données qui révèlent des détails extrêmement précieux sur les besoins, les attentes, et les habitudes de vos clients.
Le rôle de la data science est de donner un sens à ces informations, et d’orienter en conséquence la stratégie commerciale. Comprendre qui sont vos clients et ce qui les motive peut en effet vous aider à adapter votre offre. La science des données influence ainsi les efforts marketing pour permettre un bon ciblage permettant de réaliser des campagnes personnalisées et donc plus efficaces.
La data science pour suivre ses finances
Les entreprises utilisent de plus en plus la science des données pour analyser les tendances financières et prédire leurs résultats sur le moyen et long terme. Les data sur les flux de trésorerie, les actifs et les dettes d’une organisation sont autant d’indicateurs de croissance, ou au contraire de déclin financier. La science de donnée permet de mieux comprendre, et donc prévenir les risques financiers (en détectant les transactions frauduleuses, ou en modélisant les signes avant-coureurs d’un crash).
Les sous-domaines de la data science (comme l’analyse prédictive ou la gestion des risques) sont également d’excellents outils pour orienter les décisions commerciales !
La data science en logistique et supply chain
D’un point de vue opérationnel, la data science offre un ensemble de méthodes permettant d’optimiser la gestion des chaînes d’approvisionnement, des stocks, des réseaux de distribution et même du service client. À un niveau plus fondamental, elle pave la voie vers une augmentation de l’efficacité et une réduction des coûts.
La data science pour prédire les tendances sur un marché
La collecte et l’analyse de données à plus grande échelle peuvent vous permettre d’identifier les tendances émergentes sur votre marché.
Le suivi des données d’achat, de l’activité des influenceurs dans votre niche, ou encore des requêtes des moteurs de recherche peuvent en effet vous aider à déceler de nouvelles opportunités. Une belle occasion d’améliorer votre offre existante, ou de vous réorienter dans une niche plus porteuse !
La data science pour recruter des talents
Il y a encore quelques années, la journée type d’un responsable des ressources humaines consistait en grande partie à lire des CV. La data science a cependant bouleversé les processus de recrutement, en aidant les entreprises à capitaliser sur leurs data pour cibler et attirer les meilleurs talents (via les réseaux sociaux, leurs propres bases de données, les job boards, etc.).
La science des données facilite également le traitement interne des CV et des candidatures. Elle permet même la création et la conduite des tests d’aptitude basés sur la gamification !
Cependant, ces applications de la data science sont loin d’être exhaustives. Au sein d’une même organisation elle peut aussi accompagner l’optimisation des activités suivantes :
- l’analyse des clients ;
- la détection de fraudes (et plus largement la cybersécurité et la protection des données) ;
- le retargeting publicitaire ;
- la personnalisation de son site web ;
- Le service client ;
- La logistique et la gestion de la supply chain.
Quel avenir pour la data science ? Les enjeux et challenges à surmonter
À mesure que l’adoption de la science des données s’accélère, les défis qui en découlent se sont également accrus.
Des sources de données toujours plus nombreuses
La consolidation de données à partir d’informations disparates, non structurées ou semi-structurées peut être un processus complexe. Et ce, notamment parce que cela se traduit par des formats discordants, et un travail supplémentaire d’uniformisation pour faciliter (ou tout simplement permettre) leur analyse.
La normalisation des données sera donc un enjeu de taille des data scientists, s’ils ne veulent pas passer la majorité de leur temps à filtrer les erreurs. Le tri des sources, en fonction de leur pertinence et de la véracité des données qu’elles produisent, sera également une question importante à se poser en amont.
La sécurité des données
En 2020, 86 % des violations de données étaient motivées par des raisons financières. Les entreprises, en particulier celles qui centralisent des informations sensibles (financières ou médicales) devront donc se pencher sur l’épineuse question de leur protection. À l’avenir, elles seront notamment responsables de s’assurer de la confidentialité, l’intégrité et l’accessibilité des données qu’elles collectent.
La bonne nouvelle est que les outils disponibles pour sécuriser la data sont de plus en plus nombreux et efficaces. On pense à la blockchain, notamment, mais aussi au cryptage des données qui sont des pistes intéressantes à suivre…
Quelles données utilisées, et dans quel but ?
Avec un volume toujours plus massif de données disponibles, le défi est aussi de savoir lesquelles prioriser. Les organisations devront donc définir les KPI et les métriques réellement pertinentes pour leur stratégie de data science.
Un autre chantier important consistera à définir les bons cas d’usage de la science des données. Notamment en sollicitant les départements qui disposent de données ou en avoir besoin pour fonctionner de manière plus efficace.
Si vos attentes en matière de science des données ne sont pas alignées à vos objectifs finaux, tous les efforts que vous allez entreprendre seront vains !
Difficultés à recruter des profils qualifiés
La pénurie de talents est un autre problème auquel les entreprises seront de plus en plus confrontées. Des profils experts qu’il est de plus en plus difficile à trouver et à attirer dans son entreprise.
Toutes les organisations n’auront d’ailleurs pas forcément les moyens de s’offrir les services d’un Data Analyste, un Data Engineer ou un Data Architecte à temps plein. La question d’externaliser ce pan de leur activité se posera.
Avec les mêmes difficultés à élire un produit SaaS efficace ou un consultant externe réellement expérimenté !
Pour approfondir


Connect
Pour recevoir nos derniers articles sur la Data et l'Intelligence Artificielle, abonnez vous à Connect, l’email qui fait du bien à vos données.
Vous souhaitez plus d'actualités exclusives sur la data et l'IA ?
Inscrivez-vous à notre newsletter mensuelle Connect ! Recevez une fois par mois un concentré d’actualités, événements, interviews sur le domaine de la data et de l’intelligence artificielle.
